

Здравствуйте, товарищи! В интернете много онлайн ресурсов, которые предлагают разделить музыкальную композицию на составляющие до сведения — гитара, барабаны, вокал, бас и т.д. В данной статье нас интересует конкретно удаление вокала для создания минусовок из любых композиций. До недавнего времени я пользовался сервисом FADR. Он бесплатный, доступен без VPN, удобный и быстрый. Он раскладывает композицию на дорожки, после чего можно скачать каждую из них, отдельно вокал или инструментал. Явных минусов у сервера два — это одновременная работа только с одной композицией и возможность скачать дорожки только в mp3 в бесплатной версии. К тому же, скорей всего, функционал этого сервиса бесплатный не навсегда, а временно — для привлечения клиентов, и скоро станет платным, как это было с множеством ИИ сервисов, например с Coze.
К счастью, в мире нейросетей всегда найдутся умельцы, способные создать оффлайн нейросеть с кучей моделей для достижения результата, который необходим именно тебе. Среди ИИ, генерирующих изображения , такой нейросетью является Stable Diffusion, которая использует мощности вашего компьютера для работы. Кстати, про нее у меня есть статья. А среди ИИ, разделяющих музыку на составляющие такой нейросетью является Ultimate Vocal Remover. Далее будет подробная инструкция по установке и настройке.
- Заходите на страницу github, опускаетесь чуть ниже и ищете Main Download Link — качаете дистрибутив к себе на компьютер.
- Устанавливаете UVR и запускаете. Сразу скажу, что с нужными нам моделями, папка с установкой будет весить около 6 гб. А если вы меломан-экспериментатор и хотите попробовать другие модели, то намного больше. Учтите это при выборе папки при установке. Я лично установил на отдельный SSD.
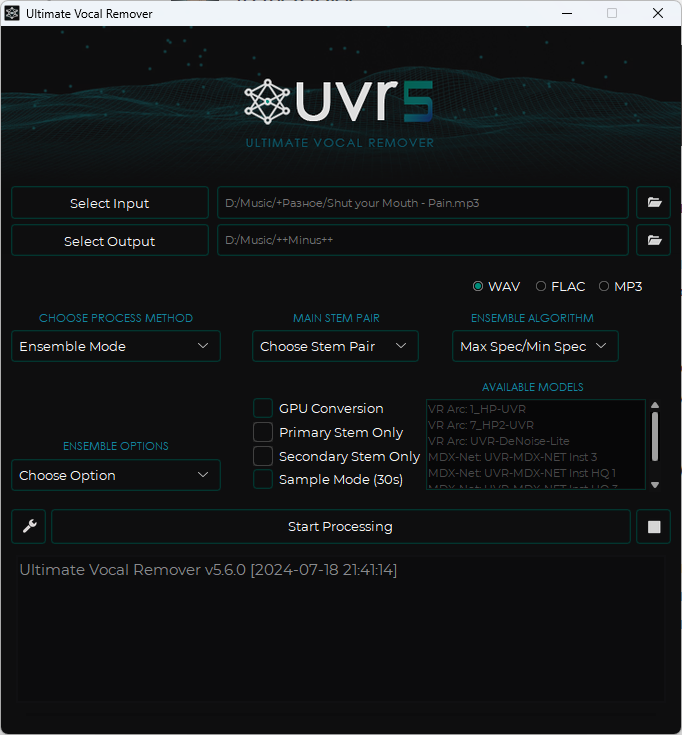
- Далее необходимо настроить программу. Жмем разводной ключ слева от кнопки Start Processing. Заходим во вкладку Additional Settings и внизу GPU Device — выбираем свою видеокарту.
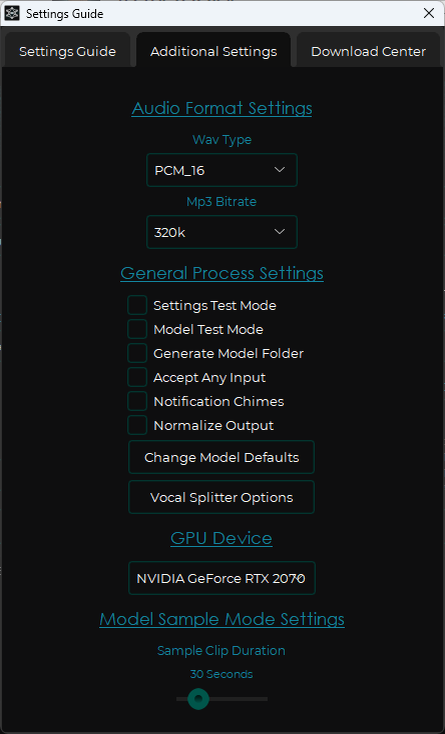
После этого необходимо скачать те модели, которые по мнению пользователей этой нейросети выдают наилучший результат. Скачиваются они во вкладке Download Center. Нам нужны следующие:
- VR_ARC: 7_HP2-UVR
- MDX_Net: UVR-MDX-NET-Inst_3
- MDX_Net: UVR-MDX-NET-Inst_HQ_1
- Demucs: v4 | htdemucs_ft
- Когда все скачалось, можно приступить к главным настройкам.
Choose Process Method — выбираем Ensemble Mode. Этот метод позволит нам использовать сразу несколько моделей и комбинировать их результат для лучшего эффекта.
Main Stem Pair — Vocals/Instrumental. Тут все логично, выбираете те дорожки, которые хотите разделить.
Ensemble Algorithm — это качество разделенных дорожек. Ставим Max Spec/Max Spec.
Ставим галку GPU Conversion.
Available Models — выделяем только те модели, что скачали ранее.
Select Input — выбираете файлы для минусовок. Можно сразу несколько.
Select Output — выбираете папку для вывода.
Также формат выходного файла можно выбрать по желанию, я оставил mp3.
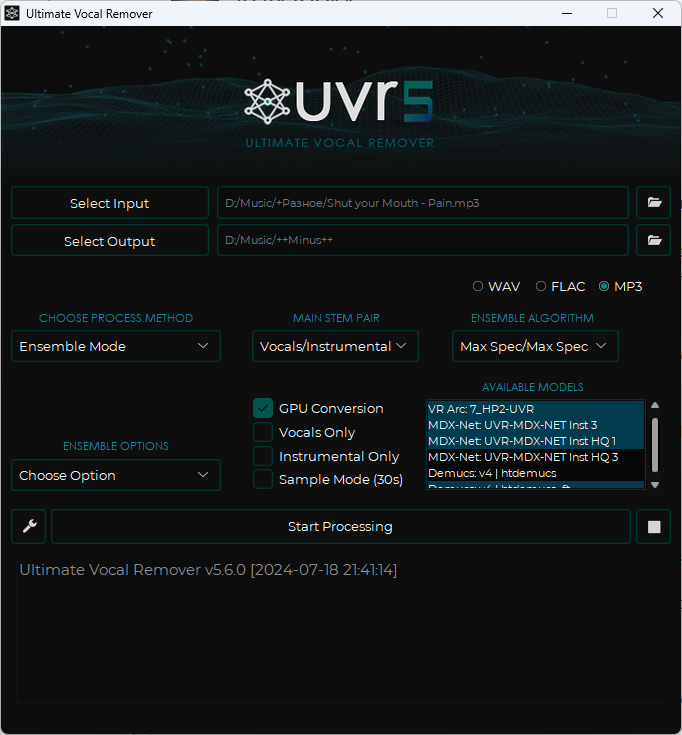
После этого можно жать кнопку Start Processing и ждать результат. Скорость зависит от мощности вашей видеокарты. На моей 2070 super одна композиция обрабатывается около 3х минут. На выходе вы получите 2 файла — с вокалом и без, скомбинированные из выбранных нами моделей. Не скомбинированные файлы, отдельно каждой модели будут лежать в соседней папке, ее можно сразу удалить, как и файл с вокалом.
Спасибо всем, кто дочитал, подписывайтесь на остальные мои соц. сети, там много всего интересного из мира 3д графики.



